What is CoDr?
Abstract
We live in a world surrounded by vast amounts of information. Impressive technological advances have allowed for the volume of information we produce to grow exponentially, to the point where we now produce in two days as much information as we produced up to 2003 (that is, from the dawn of mankind to 2003)(SCH, 2010). With this in mind, we need better tools to help us comprehend vast amounts of data. One way we can do this is by visualizing the data, hence filtering it, extracting what we need and putting it into a format our visual minds are equipped to handle. Effective data visualization helps users analyze data, makes complex data more accessible, understandable and usable.
Motivation
CODR represents a data visualization web application that will help users explore, visualize and filter data pertaining to Free Code Camp. Our goal is creating a user friendly way to interact with data so that an accurate analysis can be performed using our product. By providing different methods of visualization, our users will be able to look at a data set from different perspectives and make the most informed decisions. In order to provide a better user experience and enhance the functionality of our application, data vizualizations can be exported in PNG/SVG formats.
Github Architecture
We will use the following architecture for working on github.
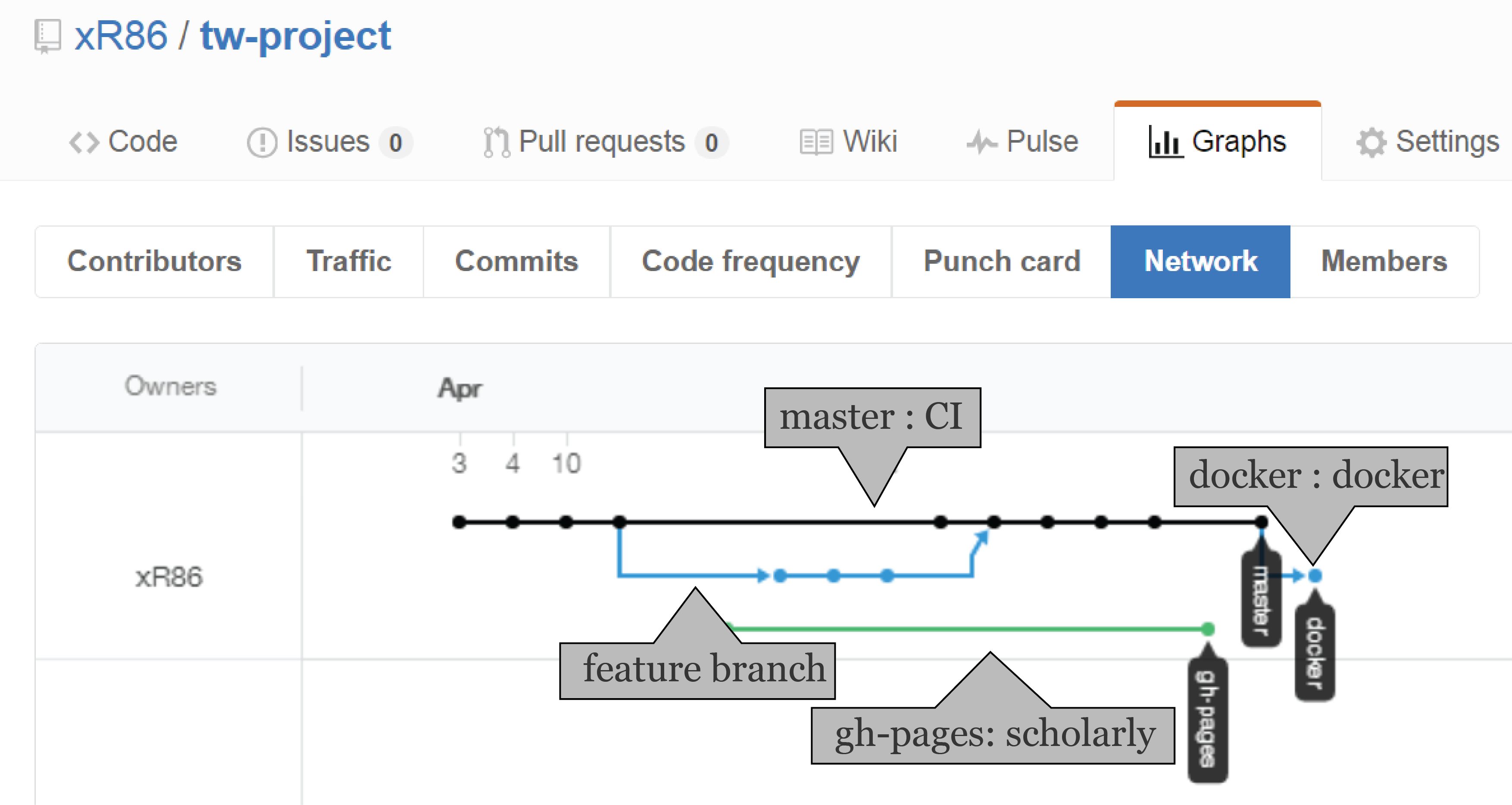
If we will cluster the application and/or use Winston, we will probably need an extra experimental branch (or nightly ?).
Architecture
CoDr will minimally implement the following architecture:
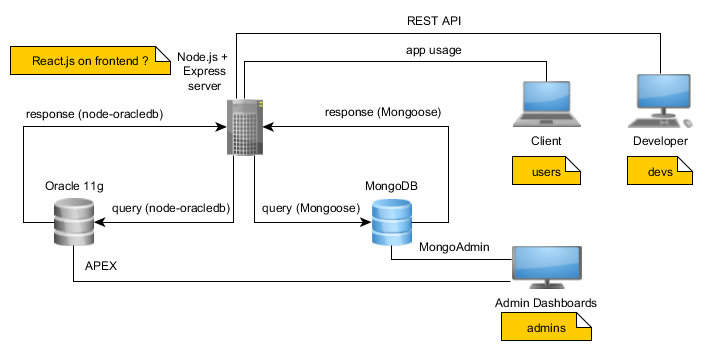
Our server will be made using the open source Node.js runtime environment plus Express framework. We made this choice because of scalability and the relatively easy learning curve involved. Because of our architectural design choice, our app will run on a single thread and will allow thousands of concurrent connections. In matter of view engine, we chose ejs (also called embedded js) for simplicity.
The data will be stored two fold, using both a classic relational database (Oracle 11g) and a NoSQL database (MongoDB). The data that will be visualized by our app will most probably be stored using Oracle. The connection between the database and our server will be provided by oracledb node module (link on npm). To help us design this database side of our app, we will make use of SQL Developer. So basically after a user connects to our server and makes a request for some data, our server will make a query to the database and then receive a response. This will form a transaction (we would prefer not keeping the database connection open all the time). Login details for our registered users will be stored using MongoDB, connected to our server by Mongoose.
We will aim though for this kind of architecture (even if we implement just a part of it):
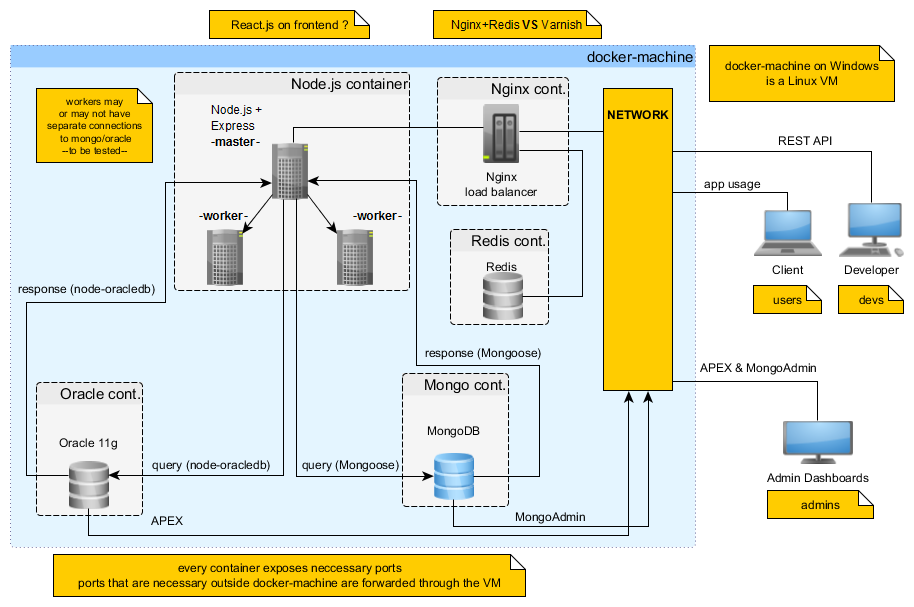
For our more advanced approach we want use Docker to wrap around our app in order to automate deployment and provide containers for the different types of applications used. Hence, we wish to use a container for the Node.js server (which may use PM2 or cluster for making several workers of the master Node server, to take advantage of the multicore nature of the hardware) and containers for the two types of databases used by our app. For optimizing resource utilization, reducing latency and for ensuring a fault-tolerant configuration we will use nginx as a HTTP load balancer & proxy and Redis as a Web cache (in theory, or practical).
Modelling the database(s)
SQL
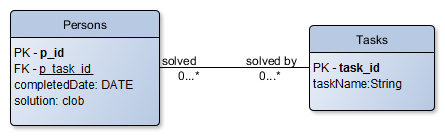
This will be the database for storing the json, after parsing it with java (you can find notes on this process here)
We will take advantage of the SQL joining, so we will break the json processed data into 2 tables: Persons and Tasks.
NoSQL
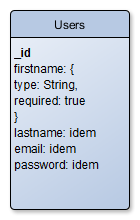
On the other side, we will use NoSQL for login, through Mongoose (for schema validation) and Passport (for the login specifically).
We start from the presumption that login through NoSQL will be faster than login through Oracle. We will check this soon.
REST API
Momentarily, our API will expose a route like /users, where users data from the json (the FreeCodeCamp json, that is) will be returned and offer the possibility of specifying the format in which the data is returned when GET is called with the querystring (eg: /users?format=xml or /users?format=json ; json will be default).
Filtering options will also include: filtering by task name (eg: /users?taskName="Waypoint: Learn how Free Code Camp Works"), completion date (full date, or combinations of year, month, day; eg: /users?completionMonth=08) or by existing solution (eg: /users?solutionExists=true).
We will probably impose a limit on the data returned for IO/network/security reasons.
Page Architecture
We will use the following architecture for structuring our ejs templates.
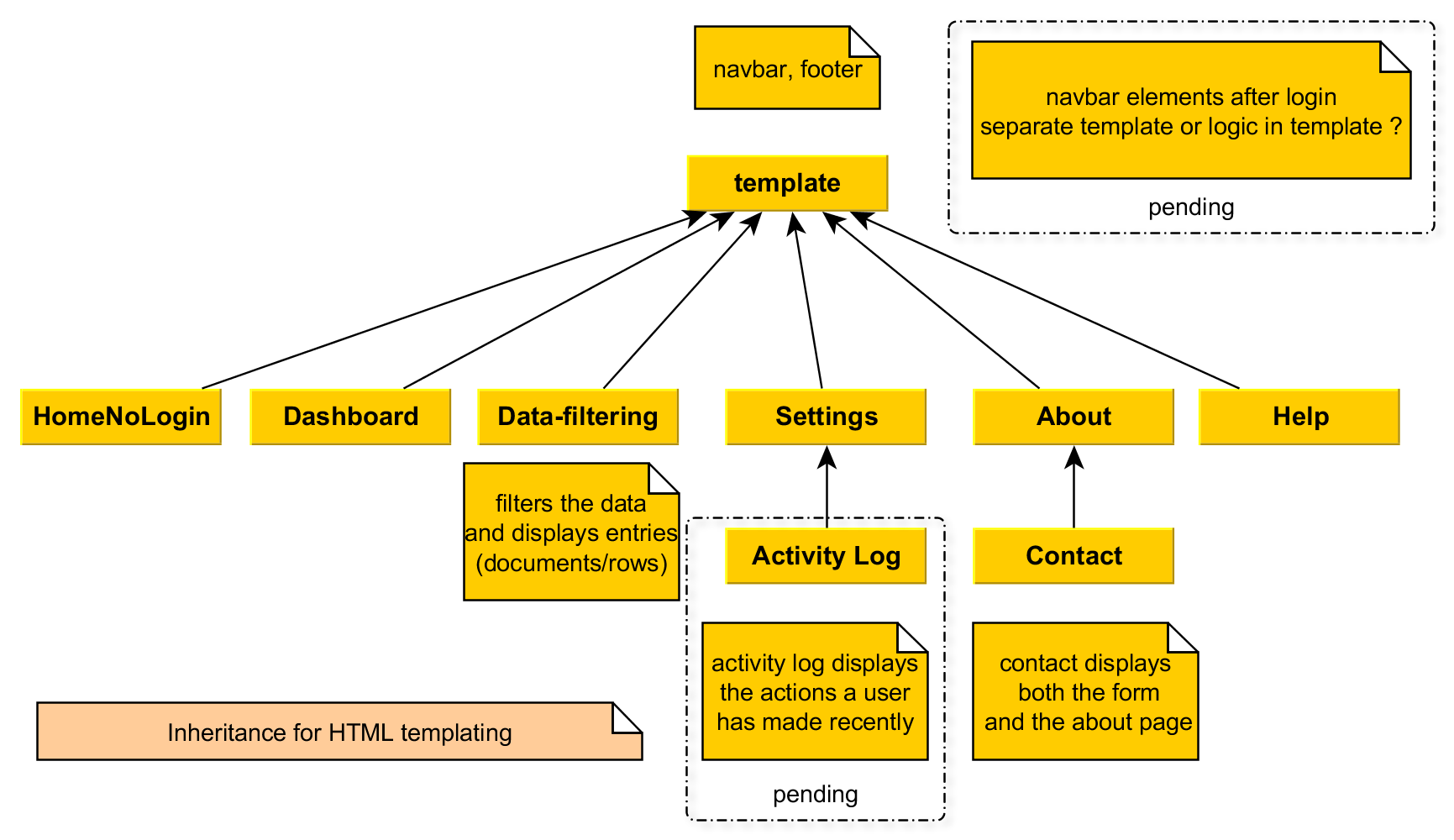
Contact page.
Template will store the navigation bar and the footer. Every page will have this. The next level of inheritance is neccessary for Contact, since we want it to extend the About page, so it isn't only a form (and we don't want to concatenate, because from an UX perspective they need to be separated).
We also have some doubts on the architecture when it comes to the activity log and template logic. We don't know yet how we would record and save user actions, or how we will display them, so this is a pending feature (we may, or may not implement it). The other issue we are thinking about is that of logging in: should we check, each time we render a view, if the user is logged in, and display some elements (the template logic approach), or should we have a separate base template for logged in users from the not logged in users ?
Additional notes on wireframes and prototype will be found on the repo's README
Acknowledgements
CoDr would like to thank the DevOps team @Yonder Iasi for the support on the Docker implementation (mainly through Vlad Baesu & Florin Asavoaie).
CoDr would like to thank Scholarly HTML for offering a template for making this academic report.
CoDr would also extend its thanks to all the people that have made Scholarly HTML possible.
We also received very useful feedback and pointers from: Alexandru Coman.
If we somehow forgot you in this list and you are too gracious to complain, we thank you all the same.
Conclusion
CoDr is currently a work in progress and is open to change. If you have feedback, simply open an issue on GitHub, or make a pull request.
CoDr currently has minimal documentation, wireframes and prototype made (almost complete). We aim to develop the full architecture, if our time allows it.
References
- SCH, 2010
- Eric Schmidt: Every 2 Days We Create As Much Information As We Did Up To 2003, by TechCrunch ; .